Nube de palabras más usadas dentro de los lenguajes de programación Javascript, React, CSS, HTML, Java, Python, Lua, PHP, Ruby, C+, Perl, C#, Scala, Go, SQL, Rust, Lisp, Clojure, Kotlin, CMake, Swift, Haskel, Elixir, Objective C, F#, Elm, PureScript, Pascal, R, Erlang, VimL, Groovy.
Los datos han sido extraídos de los diferentes repositorios de Github.
































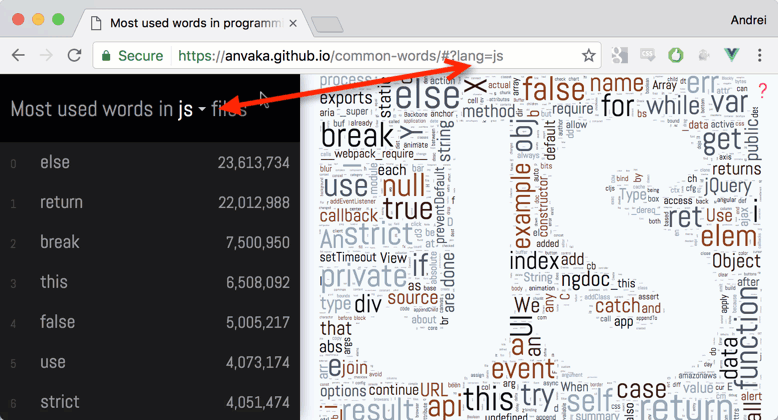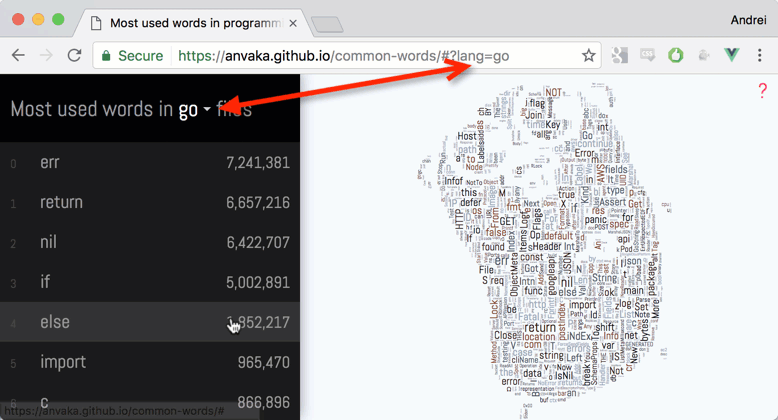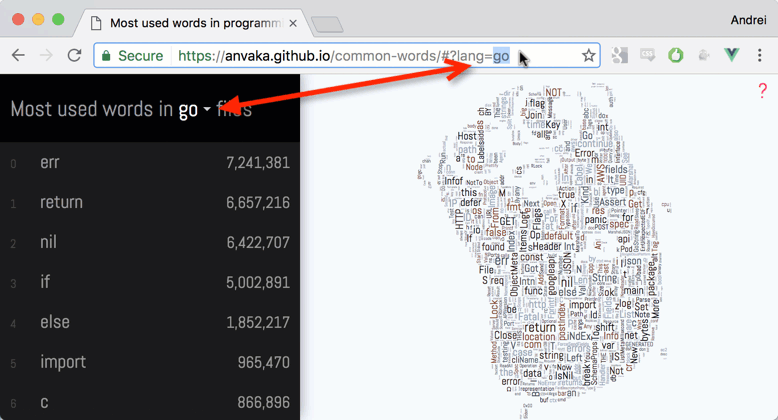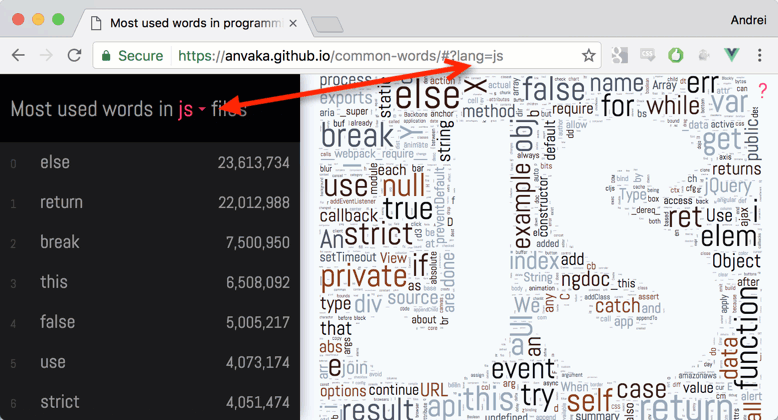
Nube de Palabras de Javascript
 Insertar Javascript⛓ Conocer Palabras
Insertar Javascript⛓ Conocer Palabras
Nube de Palabras de React
 Insertar React⛓ Conocer Palabras
Insertar React⛓ Conocer Palabras
Nube de Palabras de CSS
 Insertar CSS⛓ Conocer Palabras
Insertar CSS⛓ Conocer Palabras
Nube de Palabras de HTML
 Insertar HTML⛓ Conocer Palabras
Insertar HTML⛓ Conocer Palabras
Nube de Palabras de Java
 Insertar Java⛓ Conocer Palabras
Insertar Java⛓ Conocer Palabras
Nube de Palabras de Python
 Insertar Nube Python⛓ Conocer Palabras
Insertar Nube Python⛓ Conocer Palabras
Nube de Palabras de Lua
 Insertar Nube Lua⛓ Conocer Palabras
Insertar Nube Lua⛓ Conocer Palabras
Nube de Palabras de PHP
 Insertar PHP⛓ Conocer Palabras
Insertar PHP⛓ Conocer Palabras
Nube de Palabras de Ruby
 Insertar Ruby⛓ Conocer Palabras
Insertar Ruby⛓ Conocer Palabras
Nube de Palabras de C+
 ? Insertar C+⛓ Conocer Palabras
? Insertar C+⛓ Conocer Palabras
Nube de Palabras de Perl
 Insertar Perl⛓ Conocer Palabras
Insertar Perl⛓ Conocer Palabras
Nube de Palabras de C

Nube de Palabras de Scala
 ? Insertar Scala⛓ Conocer Palabras
? Insertar Scala⛓ Conocer Palabras
Nube de Palabras de Go

Nube de Palabras de SQL
 Insertar SQL⛓ Conocer Palabras
Insertar SQL⛓ Conocer Palabras
Nube de Palabras de Rust
 ? Insertar Rust⛓ Conocer Palabras
? Insertar Rust⛓ Conocer Palabras
Nube de Palabras de Lisp
 Insertar Lisp⛓ Conocer Palabras
Insertar Lisp⛓ Conocer Palabras
Nube de Palabras de Clojure
 Insertar Clojure⛓ Conocer Palabras
Insertar Clojure⛓ Conocer Palabras
Nube de Palabras de Kotlin
 Insertar Kotlin⛓ Conocer Palabras
Insertar Kotlin⛓ Conocer Palabras
Nube de Palabras de CMake
 Insertar CMake⛓ Conocer Palabras
Insertar CMake⛓ Conocer Palabras
Nube de Palabras de Swift
 Insertar Swift⛓ Conocer Palabras
Insertar Swift⛓ Conocer Palabras
Nube de Palabras de Haskell
 Insertar Haskell⛓ Conocer Palabras
Insertar Haskell⛓ Conocer Palabras
Nube de Palabras de Elixir
 ? Insertar Elixir⛓ Conocer Palabras
? Insertar Elixir⛓ Conocer Palabras
Nube de Palabras de Objective C
 ? Insertar Objective C⛓ Conocer Palabras
? Insertar Objective C⛓ Conocer Palabras
Nube de Palabras de F

Nube de Palabras de Elm
 Insertar Elm⛓ Conocer Palabras
Insertar Elm⛓ Conocer Palabras
Nube de Palabras de PureScript
 Insertar PureScript⛓ Conocer Palabras
Insertar PureScript⛓ Conocer Palabras
Nube de Palabras de Pascal
 Insertar Pascal⛓ Conocer Palabras
Insertar Pascal⛓ Conocer Palabras
Nube de Palabras de R

Nube de Palabras de Erlang
 ? Insertar Erlang⛓ Conocer Palabras
? Insertar Erlang⛓ Conocer Palabras
Nube de Palabras de VimL
 Insertar VimL⛓ Conocer Palabras
Insertar VimL⛓ Conocer Palabras
Nube de Palabras de Groovy
 Insertar Groovy⛓ Conocer Palabras
Insertar Groovy⛓ Conocer Palabras
Proyecto
Esta visualización muestra qué palabras se usan con mayor frecuencia en diferentes lenguajes de programación.
El índice se creó entre mediados y finales de 2016 a partir de 3 milliones de repositorios públicos de código abierto de GitHub. Los resultados se presentan como nubes de palabras y texto.
¿Cómo se recopilaron los datos?
Extraje](https://bigquery.cloud.google.com/dataset/bigquery-public-data:github_repos) palabras individuales del conjunto de datos github_repos usando BigQuery. Se extrae una palabra junto con las 10 líneas principales de código donde apareció esta palabra.
Aplico varias restricciones antes de guardar palabras individuales:
- La línea donde aparece esta palabra debe tener menos de 120 caracteres. Esto me ayuda a filtrar el código no escrito por un humano, como JavaScript minificado.
- Ignoro la puntuación (
, ; : .), los operadores (+ - * ...) ynumbers. Entonces, si la línea esa+b + 42, entonces solo se extraen dos palabras:ayb. - Ignoro las líneas con “marcadores de licencia”, palabras que aparecen predominantemente dentro del texto de la licencia (p
license. Ej .noninfringement, Etc. ). El texto de la licencia es muy común en el código. Fue interesante verlo al principio, pero abrumador al final, así que lo filtré. - Las palabras son mayúsculas y minúsculas:
Thisythisse contarán como dos palabras separadas.
En esta sección profundizamos en la extracción de palabras. Si no está interesado, vaya al algoritmo de nubes de palabras.
Los datos provienen del conjunto de datos públicos de GitHub, indexados por BigQuery: github_repos.
BigQuery almacena el contenido de cada archivo indexado en una tabla como texto sin formato:
| ID de archivo | Contenido |
|---|---|
| Archivo 1.h | // Contenido del archivo 1 \ n # ifndef FOO \ n # define FOO … |
| Archivo 2.h | // Contenido del archivo 2 \ n # ifndef BAR \ n # define BAR … |
Para construir una nube de palabras necesitamos una
weight
escala de cada palabra en consecuencia.
Para obtener el peso, podríamos dividir el texto en palabras individuales y luego agrupar la tabla por cada palabra:
| Palabra | Contar |
|---|---|
| Archivo | 2 |
| contenido | 2 |
| … | … |
Desafortunadamente, este enfoque ingenuo hace exactamente lo que a la gente no le gusta de las nubes de palabras: cada palabra se sacará de contexto.
Quería evitar este problema y permitir que las personas exploren cada palabra junto con sus contextos.
Para lograr esto, creé una tabla temporal ( código ), que en lugar de contar palabras individuales cuenta líneas:
| Línea | Contar |
|---|---|
| // Contenido del archivo 1 | 1 |
| #ifndef FOO | 1 |
| #define FOO | 1 |
| … | … |
Esto me dio “contextos” para cada palabra y redujo el tamaño general de los datos de dos terabytes a
~12GB
.
Para obtener las mejores palabras de esta tabla, podemos emplear la técnica mencionada anteriormente de dividir el contenido de la línea en palabras individuales y luego agrupar la tabla por cada palabra. También podemos obtener el contexto de una palabra si mantenemos la línea original en una tabla intermedia:
| Línea | Palabra |
|---|---|
| // Contenido del archivo 1 | Archivo |
| // Contenido del archivo 1 | contenido |
| #ifndef FOO | ifndef |
| #ifndef FOO | FOO |
| … | … |
A partir de esta representación intermedia, podemos usar la función de ventana SQL para agrupar por palabra y obtener las 10 líneas principales para cada palabra (más información aquí: Seleccione los 10 registros principales para cada categoría )
El código de extracción actual se puede encontrar aquí: extract_words.sql
Nota 1: Mi SQL-fu está en el jardín de infantes, así que avíseme si encuentra un error o quizás la forma más adecuada de obtener los datos. Mientras el script actual está funcionando, creo que puede haber casos en que los resultados estén ligeramente sesgados.
Nota 2: BigQuery es asombroso. Es potente, flexible y rápido. Enormes felicitaciones a las personas increíbles que trabajan en él.
¿Cómo se representan las nubes de palabras?
En el corazón de las nubes de palabras se encuentra un algoritmo muy simple:
for each word `w`:
repeat:
place word `w` at random point (x, y)
until `w` does not intersect any other word
Para evitar que el bucle interno se ejecute indefinidamente, podemos intentar solo un número limitado de veces y / o reducir el tamaño de fuente de la palabra si no encaja.
Si nos alejamos un poco de las palabras, podemos formular este problema en términos de rectángulos: para cada rectángulo, intente colocarlo en un lienzo, hasta que no se cruce con ningún otro píxel.
Obviamente, cuando el lienzo está muy ocupado, encontrar un lugar para un nuevo rectángulo puede ser desafiante o incluso imposible.
Varias implementaciones intentaron acelerar este algoritmo indexando el espacio ocupado:
- Use la tabla de área sumada para determinar rápidamente, en el tiempo O (1), si un nuevo rectángulo candidato se cruza con algo debajo. La desventaja de este método es que cada actualización del lienzo requiere actualizar toda la tabla, lo que da un mal rendimiento;
- Mantenga algún tipo de información
R-treepara saber rápidamente si un nuevo rectángulo candidato se cruza con algo debajo de él. La búsqueda de intersección en este enfoque es más lenta que en las tablas de área sumadas, pero el mantenimiento del índice es más rápido.
Creo que el principal inconveniente de estos dos métodos es que todavía podemos obtener un punto inicial incorrecto muchas veces antes de encontrar un lugar que se ajuste al nuevo rectángulo.
Quería probar algo diferente. Quería crear un índice que me permitiera elegir rápidamente un rectángulo lo suficientemente grande como para caber en mis nuevos rectángulos entrantes. Haga un índice del espacio libre, no ocupado.
Elijo un quadtree para ser mi índice. Cada nodo no hoja en el árbol contiene información sobre cuántos píxeles libres están disponibles debajo. En el nivel más básico, esto puede responder de inmediato a la pregunta: “¿Hay suficiente espacio para los
M
píxeles?”. Si un quad tiene menos píxeles disponibles que
M
, entonces no hay necesidad de mirar adentro.
Eche un vistazo a este árbol cuádruple para el logotipo de JavaScript:

Los rectángulos blancos vacíos son quads con espacio disponible. Si nuestro rectángulo candidato es más pequeño que cualquiera de estos quads vacíos, podríamos colocarlo inmediatamente dentro de dicho quad.
Un enfoque simple con índice quadtree da resultados decentes, sin embargo, también es susceptible a artefactos visuales. Puede ver los bordes de los cuadrantes: no se puede colocar texto en la intersección de los quads:

El
largest quad
enfoque también puede perder oportunidades. ¿Qué pasa si no hay un solo quad lo suficientemente grande como para caber en un nuevo rectángulo, pero si se une con los quads vecinos se puede encontrar un ajuste?
De hecho, unir quads ayuda a encontrar lugares para nuevas palabras, además de eliminar artefactos visuales. Muchos quads están unidos, y es probable que el texto aparezca en la intersección de dos quads:

Mi código final para la generación de nube de palabras quadtree no se publica. No creo que esté listo para ser reutilizado en ningún otro lado.
¿Cómo se creó el sitio web?
Renderizando texto
En general, estuve contento con la velocidad alcanzada de generación de nube de palabras. Sin embargo, todavía era demasiado lento para el
common-words
sitio web.
Estoy usando SVG para representar cada palabra en una pantalla. Representar solo tantos elementos de texto puede detener el hilo de la interfaz de usuario durante un par de segundos. Simplemente no hay suficiente tiempo de CPU para exprimir el cálculo del diseño del texto. La buena noticia es que no tenemos que hacerlo.
En lugar de calcular el diseño de las palabras una y otra vez cada vez que abres una página, decidí calcular el diseño una vez y almacenar los resultados en un archivo JSON. Esto me ayudó a centrarme en la optimización de hilos de la interfaz de usuario.
Para evitar el bloqueo de la interfaz de usuario durante largos períodos de tiempo, necesitamos agregar palabras de forma asincrónica. Dentro de un ciclo de bucle de eventos, agregamos N palabras y permitimos que el navegador maneje los comandos y actualizaciones del usuario. En el segundo ciclo de bucle agregamos más, y así sucesivamente. Para estos fines, hice anvaka / rafor, que es un
for
iterador de bucle asíncrono que se adapta y distribuye la carga de la CPU a través de múltiples ciclos de bucle de eventos.
Menú y zoom
El sitio web admite mapas de Google como la navegación en la escena SVG. También es móvil y compatible con el teclado. Todas estas características son implementadas por la biblioteca panzoom.
Estructura de aplicación
Estoy usando vue.js como mi marco de representación. Principalmente porque es muy simple y rápido. Los componentes de un solo archivo y la recarga en caliente agilizan el desarrollo.
Todo el estado de la aplicación se almacena en un solo objeto y los archivos de idiomas individuales se cargan cuando el usuario selecciona el elemento correspondiente de un menú desplegable.
Como mi despachador de mensajes, estoy usando ngraph.events, una biblioteca de mensajes muy pequeña que se enfoca en la velocidad.
Utilizo anvaka / query-state para almacenar el idioma seleccionado actualmente en la cadena de consulta.
Resumen de herramientas
- https://github.com/anvaka/query-state : permite almacenar el estado de la aplicación en la cadena de consulta. Admite actualizaciones bidireccionales:
query string <-> application state - https://github.com/anvaka/rafor : iteración asincrónica sobre la matriz, sin bloquear el hilo de la interfaz de usuario. Este módulo se adapta a la cantidad de trabajo por ciclo, por lo que hay suficiente tiempo de CPU para mantener la respuesta de la interfaz de usuario.
- https://github.com/anvaka/simplesvg : envoltorio muy simple en la parte superior de los elementos DOM de SVG, que proporciona una fácil manipulación.
- https://github.com/anvaka/panzoom : una biblioteca que permite la panorámica y el zoom de una escena SVG similar a los mapas de Google.
¿Por qué nubes de palabras?
Las nubes de palabras en general se consideran malas por varias razones:
- Sacan palabras de su contexto. Por
goodlo tanto , no necesariamente significa que algo es bueno (por ejemplo, cuandonotse eliminó la palabra de la visualización) - Escalan palabras para caber dentro de una imagen. Entonces no se puede confiar en el tamaño de una palabra
- Dejan caer algunas palabras comunes (como
a,the,not, etc.)
Sin embargo, siempre me fascinaron los algoritmos que ajustan las palabras dentro de una forma determinada para producir una nube de palabras.
Pasé los últimos meses de mi tiempo libre desarrollando mi propio algoritmo de nube de palabras. Y este sitio web nació. Fue divertido :).
Fuente