Por John Lunney, Robert van Gent y Scott Ritchie
con Diane Bates y Niall Richard Murphy
Un sistema complejo que funciona invariablemente ha evolucionado a partir de un sistema simple que funcionaba.
La simplicidad es un objetivo importante para los SRE, ya que se correlaciona fuertemente con la confiabilidad: el software simple se rompe con menos frecuencia y es más fácil y rápido de reparar cuando se rompe. Los sistemas simples son más fáciles de entender, más fáciles de mantener y más fáciles de probar.
Para las SRE, la simplicidad es un objetivo de un extremo a otro: debe extenderse más allá del código mismo a la arquitectura del sistema y las herramientas y procesos utilizados para administrar el ciclo de vida del software. Este capítulo explora algunos ejemplos que demuestran cómo los SRE pueden medir, pensar y fomentar la simplicidad.
Midiendo la complejidad
Medir la complejidad de los sistemas de software no es una ciencia absoluta. Hay varias formas de medir la complejidad del código de software, la mayoría de las cuales son bastante objetivas. 1 Quizás el estándar más conocido y más ampliamente disponible es el de la complejidad del código ciclomático, que mide el número de rutas de código distintas a través de un conjunto específico de declaraciones. Por ejemplo, un bloque de código sin bucles ni condicionales tiene un número de complejidad ciclomática (CCN) de 1. La comunidad de software es bastante buena para medir la complejidad del código y existen herramientas de medición para varios entornos de desarrollo integrados (incluido Visual Studio, Eclipse e IntelliJ). Somos menos expertos en comprender si la complejidad medida resultante es necesaria o accidental, cómo la complejidad de un método puede influir en un sistema más grande y qué enfoques son los mejores para la refactorización.
Por otro lado, las metodologías formales para medir la complejidad del sistema son raras. 2 Puede tener la tentación de probar un enfoque del tipo CCN para contar el número de entidades distintas (por ejemplo, microservicios) y las posibles rutas de comunicación entre ellas. Sin embargo, para la mayoría de los sistemas considerables, ese número puede crecer enormemente muy rápidamente.
Algunos proxies más prácticos para la complejidad a nivel de sistemas incluyen:
Tiempo de entrenamiento
- ¿Cuánto tiempo le toma a un nuevo miembro del equipo estar de guardia? La documentación deficiente o faltante puede ser una fuente importante de complejidad subjetiva.
Tiempo de explicación
- ¿Cuánto tiempo lleva explicar una vista completa de alto nivel del servicio a un nuevo miembro del equipo (por ejemplo, diagramar la arquitectura del sistema en una pizarra y explicar la funcionalidad y las dependencias de cada componente)?
Diversidad administrativa
- ¿De cuántas formas hay de configurar ajustes similares en diferentes partes del sistema? ¿Se almacena la configuración en un lugar centralizado o en varias ubicaciones?
Diversidad de configuraciones implementadas
- ¿Cuántas configuraciones únicas se implementan en producción (incluidos binarios, versiones binarias, indicadores y entornos)?
Envejecer
- ¿Qué tan antiguo es el sistema? La Ley de Hyrum establece que, con el tiempo, los usuarios de una API dependen de todos los aspectos de su implementación, lo que genera comportamientos frágiles e impredecibles.
Si bien en ocasiones vale la pena medir la complejidad, es difícil. Sin embargo, no parece haber una oposición seria a las observaciones de que:
- En general, la complejidad aumentará en los sistemas de software vivos a menos que exista un esfuerzo compensatorio.
- Hacer ese esfuerzo es algo que vale la pena hacer.
La simplicidad es de un extremo a otro y los SRE son buenos para eso
Generalmente, los sistemas de producción no están diseñados de manera holística; más bien, crecen orgánicamente. Acumulan componentes y conexiones a lo largo del tiempo a medida que los equipos agregan nuevas funciones y lanzan nuevos productos. Si bien un solo cambio puede ser relativamente simple, cada cambio afecta a los componentes que lo rodean. Por lo tanto, la complejidad general puede volverse abrumadora rápidamente. Por ejemplo, agregar reintentos en un componente puede sobrecargar una base de datos y desestabilizar todo el sistema, o hacer que sea más difícil razonar sobre la ruta que sigue una consulta determinada a través del sistema.
Con frecuencia, el costo de la complejidad no afecta directamente al individuo, al equipo o al rol que lo presenta; en términos económicos, la complejidad es una externalidad. En cambio, la complejidad impacta a quienes continúan trabajando en ella y alrededor de ella. Por lo tanto, es importante tener un campeón para la simplicidad del sistema de un extremo a otro.
Los SRE se adaptan naturalmente a esta función porque su trabajo requiere que traten el sistema como un todo. 3 Además de admitir sus propios servicios, los SRE también deben conocer los sistemas con los que interactúa su servicio. Los equipos de desarrollo de productos de Google a menudo no tienen visibilidad sobre los problemas de toda la producción, por lo que encuentran valioso consultar a los SRE para obtener asesoramiento sobre el diseño y el funcionamiento de sus sistemas.
Nota
Acción del lector:
antes de que un ingeniero se ponga de guardia por primera vez, anímelo a dibujar (y volver a dibujar) los diagramas del sistema. Mantenga un conjunto canónico de diagramas en su documentación: son útiles para los nuevos ingenieros y ayudan a los ingenieros más experimentados a mantenerse al día con los cambios.
En nuestra experiencia, los desarrolladores de productos generalmente terminan trabajando en un subsistema o componente estrecho. Como resultado, no tienen un modelo mental para el sistema en general y sus equipos no crean diagramas de arquitectura a nivel del sistema. Estos diagramas son útiles porque ayudan a los miembros del equipo a visualizar las interacciones del sistema y articular problemas utilizando un vocabulario común. La mayoría de las veces, encontramos que el equipo de SRE para el servicio dibuja los diagramas de arquitectura a nivel del sistema.
Nota
Acción del lector:
asegúrese de que un SRE revise todos los documentos de diseño principales y que los documentos del equipo muestren cómo el nuevo diseño afecta la arquitectura del sistema. Si un diseño agrega complejidad, la SRE podría sugerir alternativas que simplifiquen el sistema.
Estudio de caso 1: Simplicidad de API de un extremo a otro
Fondo
En un puesto anterior, uno de los autores del capítulo trabajó en una startup que usaba una
bag
estructura de datos clave / valor en sus bibliotecas centrales. Las RPC (llamadas a procedimientos remotos) tomaron un
bag
y devolvieron a
bag
; Los parámetros reales se almacenaron como pares clave / valor dentro de
bag
. Las bibliotecas principales admitían operaciones comunes en
bag
correos electrónicos, como serialización, cifrado y registro. Todas las API y las bibliotecas centrales fueron extremadamente simples y flexibles: éxito, ¿verdad?
Lamentablemente, no: los clientes de las bibliotecas terminaron pagando una penalización por la naturaleza abstracta de las API principales. El conjunto de claves y valores (y tipos de valores) debía documentarse cuidadosamente para cada servicio, pero por lo general no era así. Además, mantener la compatibilidad hacia atrás / adelante se volvió difícil a medida que se agregaban, eliminaban o cambiaban parámetros con el tiempo.
Lecciones aprendidas
Los tipos de datos estructurados como Protocol Buffers de Google o Apache Thrift pueden parecer más complejos que sus alternativas abstractas de propósito general, pero dan como resultado soluciones de extremo a extremo más simples porque obligan a tomar decisiones de diseño y documentación por adelantado.
Estudio de caso 2: Complejidad del ciclo de vida del proyecto
Cuando revisa los espaguetis enredados de su sistema existente, puede ser tentador reemplazarlo por completo con un sistema nuevo, limpio y simple que resuelve el mismo problema. Desafortunadamente, es posible que el costo de crear un nuevo sistema manteniendo el actual no valga la pena.
Fondo
es el sistema de gestión de contenedores interno de Google. Ejecuta una gran cantidad de contenedores de Linux y tiene una amplia variedad de patrones de uso: lotes frente a producción, canalizaciones frente a servidores y más. A lo largo de los años, Borg y su ecosistema circundante crecieron a medida que cambiaba el hardware, se agregaban funciones y aumentaba su escala.
Omega estaba destinado a ser una versión más limpia y basada en principios de Borg que admitiera los mismos casos de uso. Sin embargo, el cambio planeado de Borg a Omega tuvo algunos problemas graves:
- Borg continuó evolucionando a medida que se desarrolló Omega, por lo que Omega siempre estaba persiguiendo un objetivo en movimiento.
- Las primeras estimaciones de la dificultad de mejorar Borg resultaron demasiado pesimistas, mientras que las expectativas para Omega resultaron demasiado optimistas (en la práctica, la hierba no siempre es más verde).
- No nos dimos cuenta de lo difícil que sería migrar de Borg a Omega. Millones de líneas de código de configuración en miles de servicios y muchos equipos de SRE significaron que la migración sería extremadamente costosa en términos de ingeniería y tiempo de calendario. Durante el período de migración, que probablemente tomaría años, tendríamos que admitir y mantener ambos sistemas.
Lo que decidimos hacer
, alimentamos algunas de las ideas que surgieron al diseñar Omega nuevamente en Borg. También utilizamos muchos de los conceptos de Omega para poner en marcha Kubernetes , un sistema de gestión de contenedores de código abierto.
Lecciones aprendidas
Al considerar una reescritura, piense en el ciclo de vida completo del proyecto, incluido el desarrollo hacia un objetivo en movimiento, un plan de migración completo y los costos adicionales en los que podría incurrir durante la ventana de tiempo de migración. Las API amplias con muchos usuarios son muy difíciles de migrar. No compare el resultado esperado con su sistema actual. En su lugar, compare el resultado esperado con el aspecto que tendría su sistema actual si invirtiera el mismo esfuerzo en mejorarlo. A veces, una reescritura es la mejor manera de avanzar, pero asegúrese de haber sopesado los costos y los beneficios y de no subestimar los costos.
Recuperar la simplicidad
La mayor parte del trabajo de simplificación consiste en eliminar elementos de un sistema. A veces, la simplificación es directa (por ejemplo, eliminar una dependencia de un dato no utilizado obtenido de un sistema remoto). Otras veces, la simplificación requiere un rediseño. Por ejemplo, dos partes de un sistema pueden necesitar acceso a los mismos datos remotos. En lugar de recuperarlos dos veces, un sistema más simple podría recuperar los datos una vez y reenviar el resultado.
Cualquiera que sea el trabajo, el liderazgo debe garantizar que los esfuerzos de simplificación se celebren y se prioricen explícitamente. La simplificación es eficiencia: en lugar de ahorrar recursos informáticos o de red, ahorra tiempo de ingeniería y carga cognitiva. Trate los proyectos de simplificación exitosos de la misma manera que trata los lanzamientos de funciones útiles, y mida y celebre la adición y eliminación de código por igual. 4 Por ejemplo, la intranet de Google muestra una insignia de “Asesino de códigos zombis” para los ingenieros que eliminan cantidades significativas de código.
La simplificación es una característica. Debe priorizar y simplificar los proyectos de personal y reservar tiempo para que los SRE trabajen en ellos. Si los desarrolladores de productos y los SRE no ven los proyectos de simplificación como beneficiosos para sus carreras, no los emprenderán. Considere hacer de la simplicidad un objetivo explícito para sistemas particularmente complejos o equipos sobrecargados. Cree un cubo de tiempo separado para hacer este trabajo. Por ejemplo, reserve el 10% del tiempo del proyecto de ingeniería para proyectos de “simplicidad”. 5
Nota
Acción del lector:
haga que los ingenieros realicen una lluvia de ideas sobre las complejidades conocidas del sistema y discutan ideas para reducirlas.
A medida que un sistema crece en complejidad, existe la tentación de dividir los equipos de SRE, enfocando cada nuevo equipo en partes más pequeñas del sistema. Si bien esto a veces es necesario, el alcance reducido de los nuevos equipos podría disminuir su motivación o capacidad para impulsar proyectos de simplificación más grandes. Considere la posibilidad de designar un pequeño grupo rotatorio de SRE que mantengan el conocimiento práctico de toda la pila (probablemente con menos profundidad) y puedan impulsar la conformidad y la simplificación a través de ella.
Como se mencionó anteriormente, el acto de hacer un diagrama de su sistema puede ayudarlo a identificar problemas de diseño más profundos que obstaculizan su capacidad para comprender el sistema y predecir su comportamiento. Por ejemplo, al hacer un diagrama de su sistema, puede buscar lo siguiente:
Amplificación
- Cuando una llamada devuelve un error o se agota el tiempo de espera y se vuelve a intentar en varios niveles, hace que se multiplique el número total de RPC.
Dependencias cíclicas
- Cuando un componente depende de sí mismo (a menudo indirectamente), la integridad del sistema puede verse seriamente comprometida; en particular, un arranque en frío de todo el sistema podría volverse imposible.
Estudio de caso 3: Simplificación de la telaraña de anuncios gráficos
Fondo
El negocio de anuncios gráficos de Google tiene muchos productos relacionados, incluidos algunos que se originaron a partir de adquisiciones (DoubleClick, AdMob, Invite Media, etc.). Estos productos debían adaptarse para funcionar con la infraestructura de Google y los productos existentes. Por ejemplo, queríamos que un sitio web que usara DoubleClick for Publishers pudiera mostrar anuncios elegidos por AdSense de Google; De manera similar, queríamos que los postores que usaban DoubleClick Bid Manager tuvieran acceso a las subastas en tiempo real que se ejecutan en Ad Exchange de Google.
Estos productos desarrollados de forma independiente formaban un sistema de backends interconectados sobre el que era difícil razonar. Era difícil observar lo que sucedía con el tráfico a medida que pasaba por los componentes, y proporcionar la cantidad adecuada de capacidad para cada pieza era inconveniente e impreciso. En un momento, agregamos pruebas para asegurarnos de haber eliminado todos los bucles infinitos en el flujo de consultas.
Lo que decidimos hacer
Los anuncios que ofrecían SRE eran los impulsores naturales de la estandarización: si bien cada componente tenía un equipo de desarrolladores específico, los SRE estaban disponibles para toda la pila. Una de nuestras primeras empresas fue redactar estándares de uniformidad y trabajar con equipos de desarrolladores para adoptarlos de manera incremental. Estos estándares:
- Se estableció una forma única de copiar grandes conjuntos de datos.
- Se estableció una forma única de realizar búsquedas de datos externos.
- Se proporcionaron plantillas comunes para la supervisión, el aprovisionamiento y la configuración.
Antes de esta iniciativa, los programas separados proporcionaban funcionalidad de subasta y frontend para cada producto. Como se muestra en la Figura 7-1 , cuando una solicitud de anuncio puede llegar a dos sistemas de orientación, reescribimos la solicitud para cumplir con las expectativas del segundo sistema. Esto requirió procesamiento y código adicional, y también abrió la posibilidad de bucles indeseables.
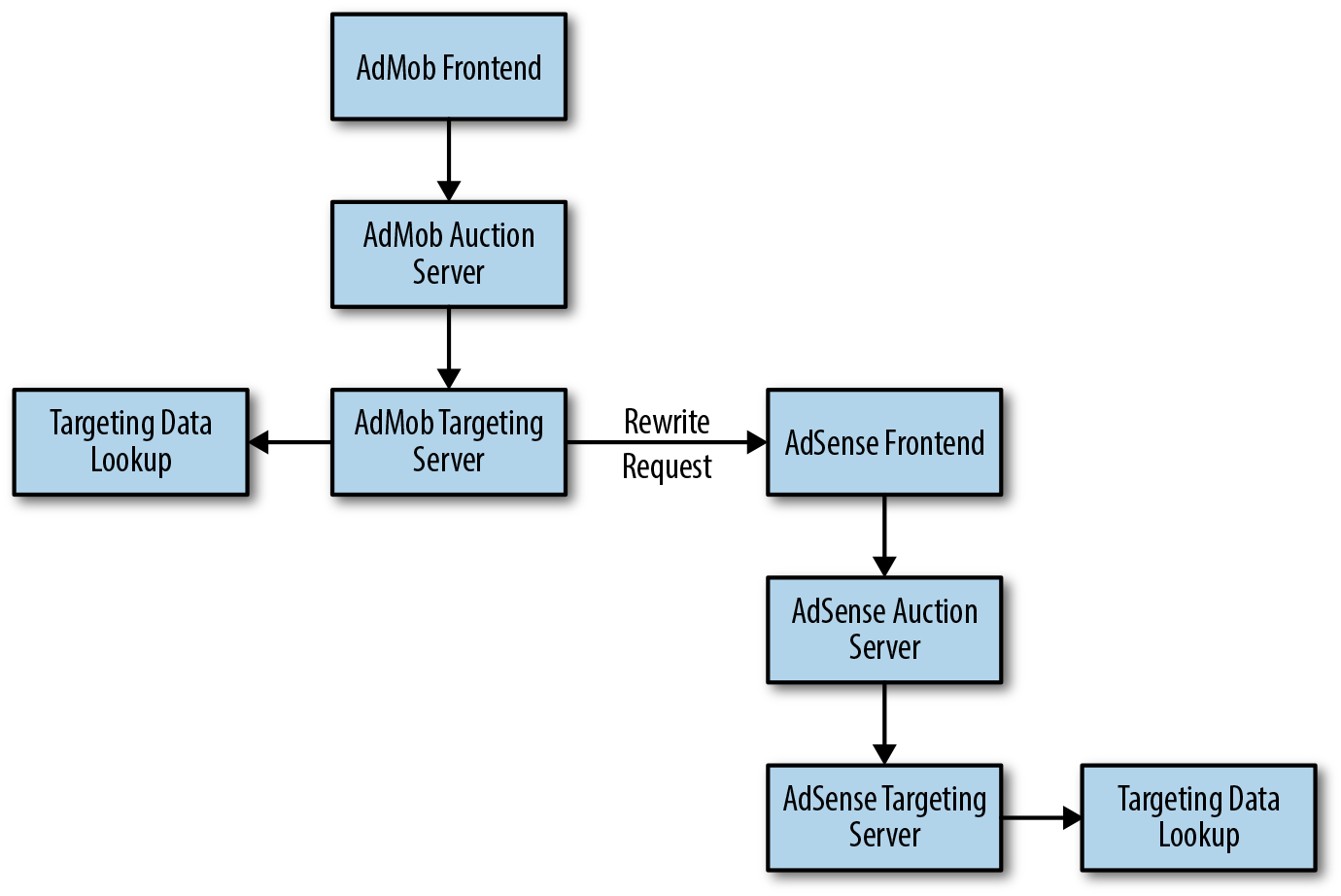
Para simplificar el sistema, agregamos lógica a los programas comunes que satisfacen todos nuestros casos de uso, junto con indicadores para proteger los programas. Con el tiempo, eliminamos los indicadores y consolidamos la funcionalidad en menos servidores.
Una vez que se unificaron los servidores, el servidor de subastas podría comunicarse directamente con ambos servidores de destino. Como se muestra en la Figura 7-2 , cuando varios servidores de destino necesitaban búsquedas de datos, la búsqueda debía realizarse solo una vez en el servidor de subastas unificado.

Lecciones aprendidas
Es mejor integrar un sistema que ya esté en ejecución en su propia infraestructura de forma incremental.
Así como la presencia de funciones muy similares en un solo programa representa un “olor a código” que indica problemas de diseño más profundos, las búsquedas redundantes en una sola solicitud representan un “olor a sistema”.
Cuando crea estándares bien definidos con la participación de SRE y los desarrolladores, puede proporcionar un plan claro para eliminar la complejidad que los gerentes tienen más probabilidades de respaldar y recompensar.
Estudio de caso 4: Ejecución de cientos de microservicios en una plataforma compartida
por Mike Curtis
Fondo
Durante los últimos 15 años, Google ha desarrollado múltiples verticales de productos exitosos (Búsqueda, Anuncios y Gmail, por nombrar algunos) y ha producido un flujo constante de sistemas nuevos y refactorizados. Muchos de estos sistemas tienen un equipo SRE dedicado y una pila de producción específica de dominio correspondiente que incluye un flujo de trabajo de desarrollo a medida, ciclos de software de integración continua y entrega continua (CI / CD) y monitoreo. Estas pilas de producción únicas incurren en gastos generales importantes en términos de mantenimiento, costos de desarrollo y participación de SRE independiente. También dificultan la transferencia de servicios (¡o ingenieros!) Entre equipos o la incorporación de nuevos servicios.
Lo que decidimos hacer
Un conjunto de equipos de SRE en el espacio de las redes sociales trabajó para converger las pilas de producción de sus servicios en una única plataforma de microservicios administrada, administrada por un solo grupo de SRE. La plataforma compartida cumple con las mejores prácticas, y agrupa y configura automáticamente muchas características previamente infrautilizadas que mejoran la confiabilidad y facilitan la depuración. Independientemente de su nivel de participación de SRE, los nuevos servicios dentro del alcance del equipo de SRE debían usar la plataforma común, y los servicios heredados debían migrar a la nueva plataforma o eliminarse gradualmente.
Después de su éxito en el espacio de las redes sociales, la plataforma compartida está ganando adopción con otros equipos SRE y no SRE en Google.
Diseño
Usamos microservicios para poder actualizar e implementar funciones rápidamente: un único servicio monolítico cambia lentamente. Los servicios se administran , no se alojan : en lugar de eliminar el control y la responsabilidad de los equipos individuales, los capacitamos para que administren sus servicios de manera efectiva por sí mismos. Proporcionamos herramientas de flujo de trabajo que los equipos de servicio pueden usar para lanzar, monitorear y más.
Las herramientas que proporcionamos incluyen una interfaz de usuario, una API y una interfaz de línea de comandos que los SRE y los desarrolladores utilizan para interactuar con su pila. Las herramientas hacen que la experiencia del desarrollador se sienta unificada, incluso cuando involucra muchos sistemas subyacentes.
Resultados
La alta calidad y el conjunto de funciones de la plataforma tuvieron un beneficio inesperado: los equipos de desarrolladores pueden ejecutar cientos de servicios sin ningún compromiso profundo de SRE.
La plataforma común también cambió la relación SRE-desarrollador. Como resultado, la participación de SRE escalonada se está volviendo común en Google. El compromiso por niveles incluye un espectro de participación de SRE, que va desde consultoría ligera y revisiones de diseño hasta un compromiso profundo (es decir, los SRE comparten las tareas de guardia).
Lecciones aprendidas
Pasar de estándares escasos o mal definidos a una plataforma altamente estandarizada es una inversión a largo plazo. Cada paso puede parecer incremental, pero en última instancia, estos pasos reducen la sobrecarga y hacen posible la ejecución de servicios a escala.
Es importante que los desarrolladores vean el valor de tal transición. Apunte a ganancias de productividad incrementales que se desbloqueen en cada etapa de desarrollo. No intente convencer a las personas para que realicen una gran refactorización que solo rinde frutos al final.
Estudio de caso 5: pDNS ya no depende de sí mismo
Fondo
Cuando un cliente en la producción de Google quiere buscar la dirección IP de un servicio, a menudo usa un servicio de búsqueda llamado Svelte. En el pasado, para encontrar la dirección IP de Svelte, el cliente utilizaba un servicio de nombres de Google llamado pDNS (DNS de producción). Se accede al servicio pDNS a través de un equilibrador de carga, que busca las direcciones IP de los servidores pDNS reales … utilizando Svelte.
Planteamiento del problema
pDNS tenía una dependencia transitiva de sí mismo, que se introdujo involuntariamente en algún momento y solo más tarde se identificó como un problema de confiabilidad. Las búsquedas normalmente no presentaban problemas porque el servicio pDNS está replicado y los datos necesarios para salir del ciclo de dependencia siempre estaban disponibles en algún lugar de la producción de Google. Sin embargo, un arranque en frío hubiera sido imposible. En palabras de un SRE, “Éramos como los habitantes de las cavernas que solo podían encender fuego corriendo con una antorcha encendida desde la última fogata”.
Lo que decidimos hacer
Modificamos un componente de bajo nivel en la producción de Google para mantener una lista de direcciones IP actuales para los servidores Svelte cercanos en el almacenamiento local para todas las máquinas de producción de Google. Además de romper la dependencia circular descrita anteriormente, este cambio también eliminó una dependencia implícita de pDNS para la mayoría de los demás servicios de Google.
Para evitar problemas similares, también introdujimos un método para incluir en la lista blanca el conjunto de servicios permitidos para comunicarse con pDNS, y trabajamos lentamente para reducir ese conjunto. Como resultado, cada búsqueda de servicio en producción ahora tiene una ruta más simple y confiable a través del sistema.
Lecciones aprendidas
Tenga cuidado con las dependencias de su servicio: use una lista blanca explícita para evitar adiciones accidentales. Además, esté atento a las dependencias circulares.
Conclusión
La simplicidad es un objetivo natural para los SRE porque los sistemas simples tienden a ser confiables y fáciles de ejecutar. No es fácil medir cuantitativamente la simplicidad (o su complejidad inversa) para sistemas distribuidos, pero existen proxies razonables, y vale la pena elegir algunos y trabajar para mejorarlos.
Debido a su comprensión integral de un sistema, los SRE se encuentran en una excelente posición para identificar, prevenir y corregir fuentes de complejidad, ya sea que se encuentren en el diseño de software, la arquitectura del sistema, la configuración, los procesos de implementación o en otros lugares. Los SRE deben participar en las discusiones de diseño desde el principio para brindar su perspectiva única sobre los costos y beneficios de las alternativas, con especial atención a la simplicidad. Los SRE también pueden desarrollar estándares de manera proactiva para homogeneizar la producción.
Como SRE, presionar por la simplicidad es una parte importante de la descripción de su trabajo. Recomendamos encarecidamente que el liderazgo de SRE empodere a los equipos de SRE para impulsar la simplicidad y recompensar explícitamente estos esfuerzos. Los sistemas inevitablemente se arrastran hacia la complejidad a medida que evolucionan, por lo que la lucha por la simplicidad requiere atención y compromiso continuos, pero vale la pena perseguirla.
1 Si está interesado en aprender más, lea esta revisión recientede las tendencias en la complejidad del software, o lea Horst Zuse, Software Complexity: Measures and Methods (Berlín: Walter de Gruyter, 1991).
2 Aunque hay ejemplos de ello, por ejemplo, “Razonamiento formal automatizado sobre los sistemas AWS” .
3 Como resultado, SRE puede ser una inversión útil para los líderes de desarrollo de productos que desean atacar la complejidad como un sustituto de la deuda técnica, pero les resulta difícil justificar ese trabajo dentro del alcance de su equipo existente.
4 Como dijo Dijkstra, “Si deseamos contar líneas de código, no debemos considerarlas como ‘líneas producidas’ sino como ‘líneas gastadas’”.
5 Reservar algo de tiempo para proyectos de simplicidad (10%, por ejemplo) no significa que el equipo tenga luz verde para introducir complejidad con el otro 90%. Simplemente significa que está dedicando un poco de esfuerzo al objetivo específico de simplificar.
Parte II. Practicas
Sobre la base de la sólida base de los principios de SRE cubiertos en Fundamentos , la Parte II profundiza en cómo realizar actividades relacionadas con SRE que Google ha considerado importantes para operar a escala.
Algunos de estos temas, como las canalizaciones de procesamiento de datos y la gestión de la carga, no se aplicarán a todas las organizaciones. Otros temas, como el manejo seguro de los cambios con la configuración y el canarying, las prácticas de guardia y qué hacer cuando las cosas van mal, contienen lecciones valiosas para cualquier equipo de SRE.
Esta parte también presenta una habilidad importante de SRE — Diseño de sistemas grandes no abstractos (NALSD) — y presenta un ejemplo detallado de cómo practicar este proceso de diseño.
A medida que pasamos de los fundamentos de la SRE a las prácticas, queríamos proporcionar un poco más de contexto sobre la relación entre las tareas operativas y el trabajo del proyecto, y la ingeniería necesaria para lograr ambos estratégicamente.
Definición del trabajo operativo (frente al trabajo del proyecto y los gastos generales)
Antes de pasar de los fundamentos a las prácticas, queríamos abordar la diferencia entre el trabajo operativo y el de proyectos, y cómo estos dos tipos de trabajo se informan entre sí. El tema es un área de debate filosófico en la comunidad SRE, por lo que este interludio presenta cómo definimos los dos tipos de trabajo en el contexto de este libro.
Las prácticas de SRE aplican soluciones de ingeniería de software a problemas operativos. Debido a que nuestros equipos de SRE son responsables del funcionamiento diario de los sistemas que apoyamos, nuestro trabajo de ingeniería a menudo se enfoca en tareas que podrían ser operaciones en otros lugares: automatizamos los procesos de liberación en lugar de realizarlos manualmente; implementamos sharding para hacer que nuestros servicios sean más confiables y menos exigentes de atención humana; Utilizamos enfoques algorítmicos para la planificación de la capacidad para que los ingenieros no tengan que realizar cálculos manuales propensos a errores.
Si bien el trabajo de ingeniería y el trabajo operativo se informan mutuamente, podemos conceptualizar el trabajo que realiza cualquier equipo de SRE como dos categorías separadas, como se muestra en la Figura II-1 . A lo largo de los años, hemos trabajado para encontrar formas de maximizar la eficiencia y la escalabilidad de cada grupo de trabajo.

Podemos dividir el trabajo operativo en cuatro categorías generales:
- Trabajo de guardia
- Solicitudes de clientes (más comúnmente, tickets)
- Respuesta al incidente
- Después de muerte
Cada una de estas categorías recibe su propio tratamiento detallado tanto en nuestro primer libro ( Ser de guardia ; Incidencias Gestión ; Postmortem Cultura: aprender de los fracasos ) y este ( eliminación de acc ; On-Call , respuesta a incidentes ; Postmortem Cultura: aprender de los fracasos ). A continuación, mostramos cómo los cuatro están interconectados y por qué es importante considerar estos tipos de trabajo como estrechamente relacionados.
¿Qué tipos de trabajo no están incluidos en el trabajo operativo? Como se muestra en la Figura II-1 , el trabajo de proyecto es el otro segmento principal del trabajo de SRE. Cuando el trabajo de interrupción de un equipo está bien administrado, tiene tiempo para el trabajo de ingeniería a más largo plazo para lograr los objetivos de estabilidad, confiabilidad y disponibilidad. Esto podría incluir proyectos de ingeniería de software destinados a mejorar la confiabilidad de un servicio, o proyectos de ingeniería de sistemas, como implementar de manera segura una nueva característica en un servicio replicado globalmente.
También se muestra en la Figura II-1 , los gastos generales son las curiosidades administrativas necesarias para trabajar en una empresa: reuniones, capacitación, respuesta a correos electrónicos, seguimiento de sus logros, llenado de papeleo, etc. Los gastos generales no son inmediatamente importantes para la discusión en cuestión, pero todos los miembros del equipo dedican tiempo a ello.
Puede notar que no mencionamos específicamente la documentación como una actividad separada. Esto se debe a que creemos que los procedimientos de documentación saludables se integran en todo su trabajo. No es necesario que piense en documentar el código, los libros de jugadas y las funciones del servicio, ni siquiera en asegurarse de que los tickets y los errores contengan toda la información que deberían, como algo independiente de su proyecto o tareas operativas. Es simplemente otra faceta de esas tareas.
En Google, especificamos que los SRE deben dedicar al menos el 50% de su tiempo al trabajo del proyecto; cualquier cosa menos genera una ingeniería insostenible y equipos agotados e insalubres. Si bien cada equipo y organización necesita encontrar su propio equilibrio saludable, hemos descubierto que aproximadamente un tercio del tiempo dedicado a tareas operativas y dos tercios del tiempo dedicado al trabajo del proyecto es casi correcto (esta proporción también informa un ideal en -tamaño de rotación de llamadas, donde sus ingenieros solo están disponibles un tercio del tiempo).
Alentamos a los equipos a realizar revisiones periódicas para rastrear si está logrando el equilibrio adecuado entre los tipos de trabajo. En Google, llevamos a cabo revisiones periódicas de excelencia en la producción (ProdEx), que permiten a los líderes senior de SRE una visión del estado de cada equipo de SRE utilizando una rúbrica claramente definida. Deberá determinar los intervalos de tiempo y la rúbrica adecuados de acuerdo con sus propias limitaciones y madurez organizacional, pero la clave aquí es generar métricas sobre la salud del equipo que pueda rastrear a lo largo del tiempo.
Recuerde una advertencia al encontrar su equilibrio ideal: un equipo que dedica muy poco tiempo a tareas operativas corre el riesgo de tener una carga operativa insuficiente. En esta situación, los ingenieros pueden empezar a olvidar aspectos cruciales del servicio del que son responsables. Puede contrarrestar la subcarga operativa asumiendo más riesgos y moviéndose más rápido, por ejemplo, acortando los ciclos de lanzamiento, impulsando más funciones por lanzamiento o realizando más pruebas de recuperación ante desastres. Si su equipo está constantemente subcargado, considere la posibilidad de incorporar servicios relacionados o devolver un servicio que ya no necesita el soporte de SRE al equipo de desarrollo (para obtener más información sobre el tamaño del equipo, consulte On-Call ).
La relación entre el trabajo operativo y el trabajo por proyectos
Si bien son clases de trabajo diferentes, el trabajo operativo y de proyecto no son preocupaciones completamente separadas. De hecho, las cuestiones planteadas en el primero deben alimentarse en el segundo: el trabajo del proyecto de SRE debe ser iniciativas estratégicas que hagan que el sistema sea más eficiente, escalable y confiable, y / o que reduzcan la carga operativa y el esfuerzo. Como se muestra en la Figura II-1 , debe haber un circuito de retroalimentación continuo entre las fuentes de carga operativa y el trabajo del proyecto que mejore sistemáticamente la producción. Este trabajo a más largo plazo podría implicar pasar a sistemas de almacenamiento más robustos, rediseñar los marcos para reducir la fragilidad o la carga de mantenimiento, o abordar las fuentes sistémicas de interrupciones e incidentes. Estas iniciativas se desarrollan e implementan a través de proyectos., definido como esfuerzos temporales (con un comienzo y un final claros) que entregan un objetivo o entregable específico.
Licencia
: Publicado por O’Reilly Media, Inc. bajo licencia CC BY-NC-ND 4.0
Relacionado
Como una de las estructuras de control básicas en la programación, los bucles son casi una adición diaria al código que escribimos. El bucle forEach clásico es uno de los primeros fragmentos de código que aprendemos a escribir como programadores. Si fueras un desarrollador de Javascript, sabrías que Javascript no es ajeno a la iteración a través de los elementos de una matriz o un mapa ¡SEGUIR LEYENDO!
Como sabemos, Sci-hub es un sitio web increíble con millones de artículos de investigación para todos los estudiantes universitarios y académicos. El sitio web de Sci-Hub se encarga de obtener los artículos de investigación y artículos de pago utilizando las credenciales que se filtran. La fuente de credenciales utilizada por este sitio web no está clara. Sin embargo, se supone que muchas de ellas son donadas, ¡SEGUIR LEYENDO!
Aunque haya sido usuario de Windows durante décadas, el sistema operativo es tan amplio y complejo que siempre existen características útiles, pero menos conocidas, que podrían sorprenderte. En este sentido, he identificado diez funciones poco conocidas de Windows que pueden potenciar su eficiencia, comodidad e incluso su experiencia de uso lúdico en su PC.

- Procesador Dual-Core Intel Pentium Gold 4425Y (2...
- Memoria RAM de 8 GB LPDDR3
- Disco SSD de 128 GB
El rumor en torno a las criptomonedas no se desvanece por mucho que existan grandes pesimistas alrededor de los malos rumores. Entonces, si consideras invertir en el mundo de las criptomonedas, deberías estar atento a las criptomonedas que se espera que tengan un buen desempeño para el resto de 2021. En los últimos tiempos, los tokens DeFi están recibiendo toda la atención y es más que ¡SEGUIR LEYENDO!
Los cambios de paradigma revolucionarios debido a los desarrollos de la robótica en todo el mundo están generando nuevos puntos de vista en muchos sectores, entre ellos en los de la industria y la tecnología. Con la ayuda de la Inteligencia Artificial, la tecnología produce resultados innovadores cada segundo y el campo de la robótica define y reconfigura su uso a cada instante. Cada día que ¡SEGUIR LEYENDO!
Bienvenidos desarrolladores web y de software, estamos en los inicios de 2023 y es posible que muchos se esten planteado sus objetivos para lo largo del año. Con anterioridad ya he compartidos las rutas de aprendizaje para un desarrollador front-end, un desarrollador full-stack o un desarrollador back-end entre otros muchos contenidos más. En este artículo, me gustaría compartir algunos de los mejores frameworks y bibliotecas para ¡SEGUIR LEYENDO!
GitHub es el lugar que debes buscar cuando intentas mejorar como desarrollador, toda la información que necesitas está disponible en algún repositorio que alguien ya se ha molestado en indexar. Sin embargo, la parte complicado es encontrar el repositorio más adecuado. Es fácil sentirse perdido en todos los repositorios disponibles dentro de GitHub. Para ayudarte, he elaborado una lista de 10 repositorios de GitHub que pueden ¡SEGUIR LEYENDO!