Escrito pPor Steven Thurgood con Jess Frame, Anthony Lenton, Carmela Quinito, Anton Tolchanov y Nejc Trdin.
Este capítulo explica cómo convertir sus SLO en alertas procesables sobre eventos importantes. Tanto nuestro primer libro SRE como este libro hablan sobre la implementación de SLO. Creemos que tener buenos SLO que midan la confiabilidad de su plataforma, según la experiencia de sus clientes, proporciona la indicación de la más alta calidad sobre cuándo debe responder un ingeniero de guardia. Aquí brindamos una guía específica sobre cómo convertir esos SLO en reglas de alerta para que pueda responder a los problemas antes de consumir demasiado de su presupuesto de errores.
Nuestros ejemplos presentan una serie de implementaciones cada vez más complejas para alertar métricas y lógicas; discutimos la utilidad y las deficiencias de cada uno. Si bien nuestros ejemplos utilizan un servicio simple impulsado por solicitudes y la sintaxis de Prometheus , puede aplicar este enfoque en cualquier marco de alerta.
Consideraciones de alerta
Para generar alertas a partir de indicadores de nivel de servicio (SLI) y un presupuesto de error, necesita una forma de combinar estos dos elementos en una regla específica. Su objetivo es recibir una notificación de un evento significativo : un evento que consume una gran fracción del presupuesto de errores.
Tenga en cuenta los siguientes atributos al evaluar una estrategia de alerta:
Precisión
- La proporción de eventos detectados que fueron significativos. La precisión es del 100% si cada alerta corresponde a un evento significativo. Tenga en cuenta que las alertas pueden volverse particularmente sensibles a eventos no significativos durante períodos de poco tráfico (discutidos en Servicios de bajo tráfico y alertas de presupuesto de errores ).
Recuerdo
- La proporción de eventos significativos detectados. La recuperación es del 100% si cada evento significativo genera una alerta.
Tiempo de detección
- Cuánto tiempo se tarda en enviar notificaciones en diversas condiciones. Los tiempos de detección prolongados pueden afectar negativamente al presupuesto de errores.
Restablecer el tiempo
- Cuánto tiempo se activan las alertas después de que se resuelve un problema. Los tiempos de reinicio prolongados pueden generar confusión o hacer que se ignoren los problemas.
Formas de alertar sobre eventos importantes
La construcción de reglas de alerta para sus SLO puede volverse bastante compleja. Aquí presentamos seis formas de configurar las alertas sobre eventos significativos, en orden de fidelidad creciente, para llegar a una opción que ofrezca un buen control sobre los cuatro parámetros de precisión, recuperación, tiempo de detección y tiempo de reinicio simultáneamente. Cada uno de los siguientes enfoques aborda un problema diferente y algunos eventualmente resuelven múltiples problemas al mismo tiempo. Los primeros tres intentos inviables funcionan hacia las últimas tres estrategias de alerta viables, siendo el enfoque 6 la opción más viable y más recomendada. El primer método es simple de implementar pero inadecuado, mientras que el método óptimo proporciona una solución completa para defender un SLO tanto a largo como a corto plazo.
Para los propósitos de esta discusión, los “presupuestos de error” y las “tasas de error” se aplican a todos los SLI, no solo a aquellos con “error” en su nombre. En la sección Qué medir: uso de SLI , recomendamos usar SLI que capturen la proporción de eventos buenos con respecto al total de eventos. El presupuesto de errores proporciona el número de eventos incorrectos permitidos y la tasa de error es la relación entre los eventos incorrectos y el total de eventos.
1: Tasa de error objetivo ≥ Umbral SLO
Para la solución más trivial, puede elegir una pequeña ventana de tiempo (por ejemplo, 10 minutos) y alertar si la tasa de error sobre esa ventana excede el SLO.
Por ejemplo, si el SLO es del 99,9% durante 30 días, avise si la tasa de error durante los 10 minutos anteriores es ≥ 0,1%:
- alerta: HighErrorRate
expr: job: slo_errors_per_request: ratio_rate10m {job = "myjob"}> = 0,001
Nota
Este promedio de 10 minutos se calcula en Prometheus con una regla de grabación:
record: job: slo_errors_per_request: ratio_rate10m
expr:
sum (rate (slo_errors [10m])) por (trabajo)
/
sum (rate (slo_requests [10m])) por (trabajo)
Si no exporta
slo_errors
y
slo_requests
desde su trabajo, puede crear la serie temporal cambiando el nombre de una métrica:
registro: slo_errors
expr: http_errors
Avisar cuando la tasa de error reciente es igual al SLO significa que el sistema detecta un gasto presupuestario de:
alertando el tamaño de la ventanaperíodo de información
La Figura 5-1 muestra la relación entre el tiempo de detección y la tasa de error para un servicio de ejemplo con una ventana de alerta de 10 minutos y un SLO del 99,9%.

La Tabla 5-1 muestra los beneficios y desventajas de alertar cuando la tasa de error inmediata es demasiado alta.
| PROS | CONTRAS |
|---|---|
| El tiempo de detección es bueno: 0,6 segundos para una interrupción total.Esta alerta se activa en cualquier evento que amenace al SLO, mostrando una buena recuperación. | La precisión es baja: la alerta se activa en muchos eventos que no amenazan al SLO. Una tasa de error del 0,1% durante 10 minutos alertaría, mientras que consumiría solo el 0,02% del presupuesto de error mensual .Llevando este ejemplo al extremo, podría recibir hasta 144 alertas por día todos los días, no actuar ante ninguna alerta y aún así cumplir con el SLO. |
2: Ventana de alerta aumentada
Podemos basarnos en el ejemplo anterior cambiando el tamaño de la ventana de alerta para mejorar la precisión. Al aumentar el tamaño de la ventana, gasta una mayor cantidad de presupuesto antes de activar una alerta.
Para mantener la tasa de alertas manejable , decide recibir una notificación solo si un evento consume el 5% del presupuesto de error de 30 días, una ventana de 36 horas:
- alerta: HighErrorRate
expr: job: slo_errors_per_request: ratio_rate36h {job = "myjob"}> 0,001
Ahora, el tiempo de detección es:
1 – SLOtasa de error× tamaño de la ventana de alerta
La Tabla 5-2 muestra los beneficios y desventajas de alertar cuando la tasa de error es demasiado alta en un período de tiempo mayor.
| PROS | CONTRAS |
|---|---|
| El tiempo de detección sigue siendo bueno: 2 minutos y 10 segundos para una interrupción completa.Mejor precisión que en el ejemplo anterior: al garantizar que la tasa de error se mantenga durante más tiempo, es probable que una alerta represente una amenaza significativa para el presupuesto de errores. | Tiempo de reinicio muy deficiente: en el caso de una interrupción del 100%, se activará una alerta poco después de 2 minutos y continuará activando durante las próximas 36 horas.Calcular velocidades en ventanas más largas puede resultar caro en términos de memoria o operaciones de E / S, debido a la gran cantidad de puntos de datos. |
muestra que, si bien la tasa de error durante un período de 36 horas ha caído a un nivel insignificante, la tasa de error promedio de 36 horas permanece por encima del umbral.
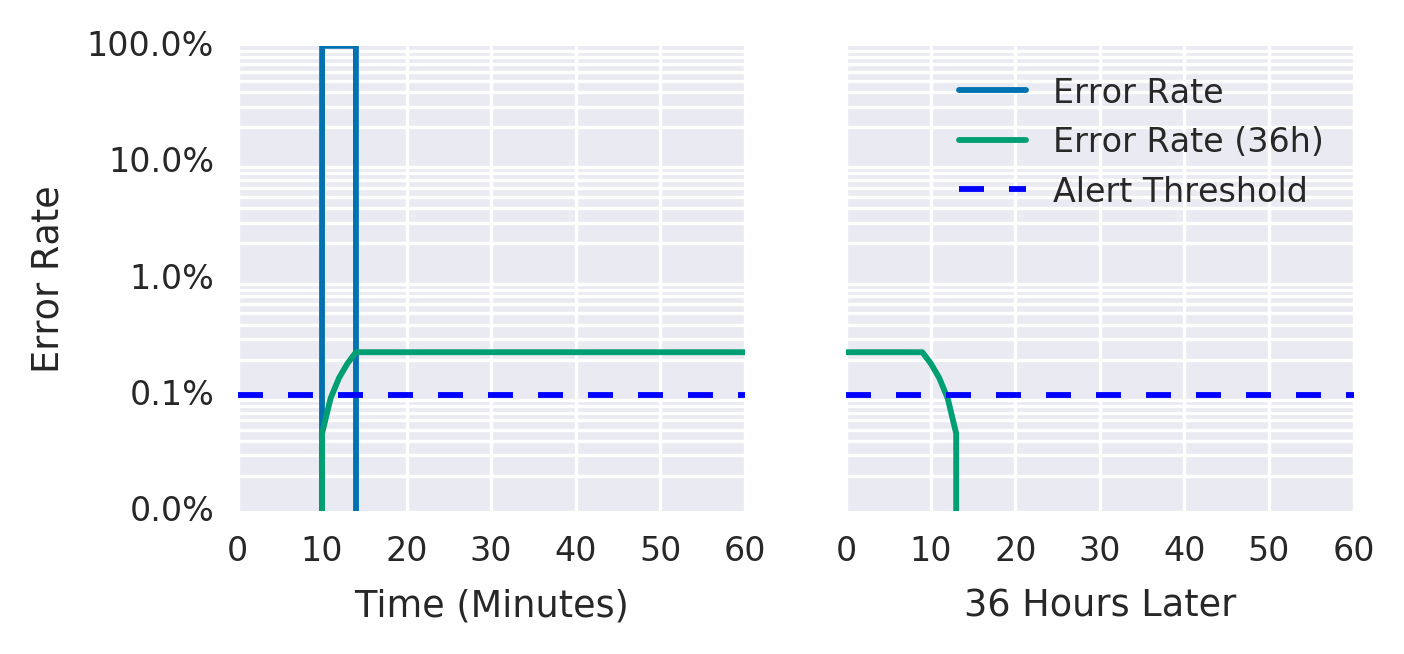
3: Incremento de la duración de la alerta
La mayoría de los sistemas de monitoreo le permiten agregar un parámetro de duración a los criterios de alerta para que la alerta no se active a menos que el valor permanezca por encima del umbral durante algún tiempo. Puede tener la tentación de usar este parámetro como una forma relativamente económica de agregar ventanas más largas:
- alerta: HighErrorRate
expr: job: slo_errors_per_request: ratio_rate1m {job = "myjob"}> 0,001
por: 1h
muestra los beneficios y desventajas de usar un parámetro de duración para las alertas.
| PROS | CONTRAS |
|---|---|
| Las alertas pueden ser de mayor precisión. Exigir una tasa de error sostenida antes de disparar significa que es más probable que las alertas correspondan a un evento significativo. | Recuperación deficiente y tiempo de detección deficiente: debido a que la duración no se ajusta a la gravedad del incidente, una interrupción del 100% alerta después de una hora, el mismo tiempo de detección que una interrupción del 0,2%. La interrupción del 100% consumiría el 140% del presupuesto de 30 días en esa hora.Si la métrica vuelve momentáneamente a un nivel dentro del SLO, el temporizador de duración se reinicia. Es posible que un SLI que fluctúe entre el SLO faltante y el SLO superado nunca avise. |
Por las razones enumeradas en la Tabla 5-3 , no recomendamos usar duraciones como parte de sus criterios de alerta basados en SLO. 1
La Figura 5-3 muestra la tasa de error promedio durante una ventana de 5 minutos de un servicio con una duración de 10 minutos antes de que se active la alerta. Una serie de picos de error del 100% que duran 5 minutos cada 10 minutos nunca activa una alerta, a pesar de consumir el 35% del presupuesto de errores.

Cada pico consumió casi el 12% del presupuesto de 30 días, pero la alerta nunca se activó.
4: Alerta sobre la tasa de quemaduras
Para mejorar la solución anterior, desea crear una alerta con un buen tiempo de detección y alta precisión. Con este fin, puede introducir una tasa de quemado para reducir el tamaño de la ventana mientras mantiene constante el gasto del presupuesto de alerta.
La tasa de quema es qué tan rápido, en relación con el SLO, el servicio consume el presupuesto de errores. La Figura 5-4 muestra la relación entre las tasas de quema y los presupuestos de error.
El servicio de ejemplo usa una tasa de quemado de 1, lo que significa que está consumiendo un presupuesto de error a una tasa que lo deja exactamente con un presupuesto 0 al final de la ventana de tiempo del SLO (consulte el Capítulo 4 de nuestro primer libro). Con un SLO del 99,9% durante una ventana de tiempo de 30 días, una tasa de error constante del 0,1% utiliza exactamente todo el presupuesto de error: una tasa de quema de 1.

La Tabla 5-4 muestra las tasas de quemado, sus tasas de error correspondientes y el tiempo que lleva agotar el presupuesto de SLO.
| VELOCIDAD DE COMBUSTIÓN | TASA DE ERROR PARA UN SLO DEL 99,9% | TIEMPO PARA EL AGOTAMIENTO |
|---|---|---|
| 1 | 0.1% | 30 dias |
| 2 | 0.2% | 15 días |
| 10 | 1% | 3 días |
| 1,000 | 100% | 43 minutos |
Si mantiene la ventana de alerta fija en una hora y decide que un gasto de presupuesto de error del 5% es lo suficientemente significativo como para notificar a alguien, puede derivar la tasa de quemado que se utilizará para la alerta.
Para las alertas basadas en la velocidad de combustión, el tiempo que tarda una alerta de incendio es:
1 – SLOtasa de error× tamaño de la ventana de alerta × tasa de quemado
El presupuesto de error consumido en el momento en que se activa la alerta es:
tasa de quemado × tamaño de la ventana de alertaperíodo
El cinco por ciento de un presupuesto de error de 30 días gastado durante una hora requiere una tasa de quema de 36. La regla de alerta ahora se convierte en:
- alerta: HighErrorRate
expr: job: slo_errors_per_request: ratio_rate1h {job = "myjob"}> 36 * 0,001
muestra los beneficios y las limitaciones de las alertas basadas en la velocidad de combustión.
| PROS | CONTRAS |
|---|---|
| Buena precisión: esta estrategia elige una parte significativa del gasto del presupuesto de error sobre el que alertar.Ventana de tiempo más corta, que es más barata de calcular.Buen tiempo de detección.Mejor tiempo de reinicio: 58 minutos. | Recuperación baja: una velocidad de grabación de 35 veces nunca alerta, pero consume todo el presupuesto de error de 30 días en 20,5 horas.Tiempo de reinicio: 58 minutos todavía es demasiado. |
5: Alertas de varias tasas de quema
Su lógica de alerta puede usar múltiples tasas de quema y ventanas de tiempo, y alertas de incendio cuando las tasas de quema superan un umbral específico. Esta opción conserva los beneficios de alertar sobre las tasas de quemado y garantiza que no pase por alto las tasas de error más bajas (pero aún significativas).
También es una buena idea configurar notificaciones de tickets para incidentes que normalmente pasan desapercibidos pero que pueden agotar su presupuesto de error si no se controlan, por ejemplo, un consumo presupuestario del 10% en tres días. Esta tasa de errores detecta eventos importantes, pero dado que la tasa de consumo presupuestario proporciona el tiempo adecuado para abordar el evento, no es necesario llamar a alguien.
Recomendamos un consumo presupuestario del 2% en una hora y un consumo presupuestario del 5% en seis horas como números de inicio razonables para la paginación, y un consumo presupuestario del 10% en tres días como una buena base para las alertas de tickets. Los números apropiados dependen del servicio y de la carga de la página de referencia. Para servicios más ocupados, y dependiendo de las responsabilidades de guardia durante los fines de semana y feriados, es posible que desee alertas de boletos para el período de seis horas.
La Tabla 5-6 muestra las tasas de combustión correspondientes y las ventanas de tiempo para los porcentajes del presupuesto SLO consumido.
| CONSUMO DE PRESUPUESTO DE SLO | VENTANA DE TIEMPO | VELOCIDAD DE COMBUSTIÓN | NOTIFICACIÓN |
|---|---|---|---|
| 2% | 1 hora | 14.4 | Página |
| 5% | 6 horas | 6 | Página |
| 10% | 3 días | 1 | Boleto |
La configuración de alerta puede parecerse a algo como:
expr: (
job: slo_errors_per_request: ratio_rate1h {job = "myjob"}> (14,4 * 0,001)
o
job: slo_errors_per_request: ratio_rate6h {job = "myjob"}> (6 * 0,001)
)
gravedad: página
expr: job: slo_errors_per_request: ratio_rate3d {job = "myjob"}> 0,001
severidad: ticket
muestra el tiempo de detección y el tipo de alerta según la tasa de error.

Múltiples velocidades de grabación le permiten ajustar la alerta para dar la prioridad adecuada según la rapidez con la que tenga que responder. Si un problema agota el presupuesto de errores en unas horas o unos días, es apropiado enviar una notificación activa. De lo contrario, una notificación basada en tickets para abordar la alerta el próximo día hábil es más apropiada. 2
La Tabla 5-7 enumera los beneficios y desventajas de usar múltiples velocidades de combustión.
| PROS | CONTRAS |
|---|---|
| Capacidad para adaptar la configuración de monitorización a muchas situaciones según la criticidad: alerta rápidamente si la tasa de error es alta; alerta eventualmente si la tasa de error es baja pero sostenida.Buena precisión, como con todos los enfoques de alerta de porciones de presupuesto fijo.Buen recuerdo, debido a la ventana de tres días.Capacidad para elegir el tipo de alerta más apropiado en función de la rapidez con la que alguien tiene que reaccionar para defender el SLO. | Más números, tamaños de ventana y umbrales para administrar y razonar.Un tiempo de reinicio aún mayor, como resultado de la ventana de tres días.Para evitar que se activen varias alertas si se cumplen todas las condiciones, debe implementar la supresión de alertas. Por ejemplo: el 10% del presupuesto invertido en cinco minutos también significa que el 5% del presupuesto se gastó en seis horas y el 2% del presupuesto se gastó en una hora. Este escenario activará tres notificaciones a menos que el sistema de monitoreo sea lo suficientemente inteligente como para evitar que lo haga. |
6: Alertas de múltiples ventanas, múltiples tasas de quemado
Podemos mejorar las alertas de tasa de grabación múltiple en la iteración 5 para notificarnos solo cuando todavía estamos consumiendo activamente el presupuesto, reduciendo así la cantidad de falsos positivos. Para hacer esto, necesitamos agregar otro parámetro: una ventana más corta para verificar si el presupuesto de error aún se está consumiendo cuando activamos la alerta.
Una buena pauta es hacer que la ventana corta sea 1/12 de la duración de la ventana larga, como se muestra en la Figura 5-6 . El gráfico muestra ambos umbrales de alerta. Después de experimentar errores del 15% durante 10 minutos, el promedio de la ventana corta supera el umbral de alerta inmediatamente y el promedio de la ventana larga supera el umbral después de 5 minutos, momento en el que la alerta comienza a dispararse. El promedio de ventana corta cae por debajo del umbral 5 minutos después de que se detengan los errores, momento en el que la alerta deja de dispararse. El promedio de la ventana larga cae por debajo del umbral 60 minutos después de que se detengan los errores.

Por ejemplo, puede enviar una alerta a nivel de página cuando excede la tasa de grabación de 14.4x durante la hora anterior y los cinco minutos anteriores. Esta alerta se activa solo una vez que ha consumido el 2% del presupuesto, pero muestra un mejor tiempo de reinicio al dejar de disparar cinco minutos más tarde, en lugar de una hora más tarde:
expr: (
job: slo_errors_per_request: ratio_rate1h {job = "myjob"}> (14,4 * 0,001)
y
job: slo_errors_per_request: ratio_rate5m {job = "myjob"}> (14,4 * 0,001)
)
o
(
job: slo_errors_per_request: ratio_rate6h {job = "myjob"}> (6 * 0,001)
y
job: slo_errors_per_request: ratio_rate30m {job = "myjob"}> (6 * 0,001)
)
gravedad: página
expr: (
job: slo_errors_per_request: ratio_rate24h {job = "myjob"}> (3 * 0,001)
y
job: slo_errors_per_request: ratio_rate2h {job = "myjob"}> (3 * 0,001)
)
o
(
job: slo_errors_per_request: ratio_rate3d {job = "myjob"}> 0,001
y
job: slo_errors_per_request: ratio_rate6h {job = "myjob"}> 0,001
)
severidad: ticket
Recomendamos los parámetros enumerados en la Tabla 5-8 como punto de partida para la configuración de alertas basada en SLO.
| GRAVEDAD | VENTANA LARGA | VENTANA CORTA | VELOCIDAD DE COMBUSTIÓN | PRESUPUESTO DE ERROR CONSUMIDO |
|---|---|---|---|---|
| Página | 1 hora | 5 minutos | 14.4 | 2% |
| Página | 6 horas | 30 minutos | 6 | 5% |
| Boleto | 3 días | 6 horas | 1 | 10% |
Hemos descubierto que las alertas basadas en múltiples tasas de quema es una forma poderosa de implementar alertas basadas en SLO.
La Tabla 5-9 muestra los beneficios y las limitaciones de usar múltiples velocidades de grabación y tamaños de ventana.
| PROS | CONTRAS |
|---|---|
| Un marco de alerta flexible que le permite controlar el tipo de alerta según la gravedad del incidente y los requisitos de la organización.Buena precisión, como con todos los enfoques de alerta de porciones de presupuesto fijo.Buen recuerdo, debido a la ventana de tres días. | Muchos parámetros para especificar, lo que puede dificultar la administración de las reglas de alerta. Para obtener más información sobre cómo administrar las reglas de alerta, consulte Alertas a gran escala . |
Servicios de poco tráfico y alertas de presupuesto de errores
El enfoque de múltiples ventanas y múltiples tasas de quemado que se acaba de detallar funciona bien cuando una tasa suficientemente alta de solicitudes entrantes proporciona una señal significativa cuando surge un problema. Sin embargo, estos enfoques pueden causar problemas a los sistemas que reciben una baja tasa de solicitudes. Si un sistema tiene un número bajo de usuarios o períodos naturales de poco tráfico (como noches y fines de semana), es posible que deba modificar su enfoque.
Es más difícil distinguir automáticamente eventos sin importancia en servicios con poco tráfico. Por ejemplo, si un sistema recibe 10 solicitudes por hora, una sola solicitud fallida da como resultado una tasa de error por hora del 10%. Para un SLO del 99,9%, esta solicitud constituye una tasa de grabación de 1000x y se paginaría inmediatamente, ya que consumió el 13,9% del presupuesto de error de 30 días. Este escenario permite solo siete solicitudes fallidas en 30 días. Las solicitudes únicas pueden fallar por una gran cantidad de razones efímeras y poco interesantes que no son necesariamente rentables de resolver de la misma manera que las grandes interrupciones sistemáticas.
La mejor solución depende de la naturaleza del servicio: ¿cuál es el impacto 3 de una única solicitud fallida? Un objetivo de alta disponibilidad puede ser apropiado si las solicitudes fallidas son solicitudes únicas de alto valor que no se reintentan. Puede tener sentido desde una perspectiva empresarial investigar cada una de las solicitudes fallidas. Sin embargo, en este caso, el sistema de alerta le notifica un error demasiado tarde.
Recomendamos algunas opciones clave para manejar un servicio con poco tráfico:
- Genere tráfico artificial para compensar la falta de señal de usuarios reales.
-
Combine servicios más pequeños en un servicio más grande con fines de supervisión.
-
Modifique el producto para que:
-
- Se necesitan más solicitudes para calificar un solo incidente como un error.
- El impacto de una sola falla es menor.
Generando tráfico artificial
Un sistema puede sintetizar la actividad del usuario para verificar posibles errores y solicitudes de alta latencia. En ausencia de usuarios reales, su sistema de monitoreo puede detectar errores sintéticos y solicitudes, por lo que sus ingenieros de guardia pueden responder a los problemas antes de que afecten a demasiados usuarios reales.
El tráfico artificial proporciona más señales con las que trabajar y le permite reutilizar su lógica de monitoreo existente y los valores de SLO. Incluso puede que ya tenga la mayoría de los componentes necesarios para generar tráfico, como sondas de caja negra y pruebas de integración.
La generación de carga artificial tiene algunas desventajas. La mayoría de los servicios que garantizan la compatibilidad con SRE son complejos y tienen una gran superficie de control del sistema. Idealmente, el sistema debería estar diseñado y construido para monitorear usando tráfico artificial. Incluso para un servicio no trivial, puede sintetizar solo una pequeña parte del número total de tipos de solicitudes de usuario. Para un servicio con estado, la mayor cantidad de estados agrava este problema.
Además, si un problema afecta a usuarios reales pero no afecta el tráfico artificial, las solicitudes artificiales exitosas ocultan la señal del usuario real, por lo que no se le notifica que los usuarios ven errores.
Combinación de servicios
Si varios servicios de poco tráfico contribuyen a una función general, la combinación de sus solicitudes en un solo grupo de nivel superior puede detectar eventos importantes con mayor precisión y con menos falsos positivos. Para que este enfoque funcione, los servicios deben estar relacionados de alguna manera: puede combinar microservicios que forman parte del mismo producto o varios tipos de solicitudes manejadas por el mismo binario.
Una desventaja de combinar servicios es que una falla total de un servicio individual puede no contar como un evento significativo. Puede aumentar la probabilidad de que una falla afecte al grupo en su conjunto eligiendo servicios con un dominio de falla compartido, como una base de datos backend común. Aún puede usar alertas de períodos más largos que eventualmente detectan estas fallas del 100% para servicios individuales.
Realización de cambios en el servicio y la infraestructura
La alerta sobre eventos importantes tiene como objetivo proporcionar un aviso suficiente para mitigar los problemas antes de que agoten todo el presupuesto de errores. Si no puede ajustar la supervisión para que sea menos sensible a los eventos efímeros y la generación de tráfico sintético no es práctico, puede considerar cambiar el servicio para reducir el impacto en el usuario de una sola solicitud fallida. Por ejemplo, podría:
- Modifique el cliente para volver a intentarlo, con retroceso y jitter exponenciales. 4
- Configure rutas de respaldo que capturen la solicitud para una eventual ejecución, que puede tener lugar en el servidor o en el cliente.
Estos cambios son útiles para los sistemas de alto tráfico, pero aún más para los de bajo tráfico: permiten más eventos fallidos en el presupuesto de errores, más señal de monitoreo y más tiempo para responder a un incidente antes de que se vuelva significativo.
Reducir el SLO o aumentar la ventana
También es posible que desee reconsiderar si el impacto de una sola falla en el presupuesto de errores refleja con precisión su impacto en los usuarios. Si una pequeña cantidad de errores hace que pierda el presupuesto de errores, ¿realmente necesita llamar a un ingeniero para que solucione el problema de inmediato? De lo contrario, los usuarios estarían igualmente contentos con un SLO más bajo. Con un SLO más bajo, se notifica a un ingeniero solo de una interrupción sostenida mayor.
Una vez que haya negociado la reducción del SLO con las partes interesadas del servicio (por ejemplo, la reducción del SLO del 99,9% al 99%), implementar el cambio es muy simple: si ya tiene sistemas para informar, monitorear y alertar basados en un Umbral SLO, simplemente agregue el nuevo valor SLO a los sistemas relevantes.
Reducir el SLO tiene una desventaja: implica una decisión de producto. Cambiar el SLO afecta otros aspectos del sistema, como las expectativas sobre el comportamiento del sistema y cuándo implementar la política de presupuesto de errores. Estos otros requisitos pueden ser más importantes para el producto que evitar algunas alertas de señal baja.
De manera similar, aumentar la ventana de tiempo utilizada para la lógica de alerta asegura que las alertas que activan las páginas son más significativas y dignas de atención.
En la práctica, utilizamos alguna combinación de los siguientes métodos para alertar sobre servicios con poco tráfico:
- Generar tráfico falso, cuando hacerlo es posible y se puede lograr una buena cobertura.
- Modificar clientes para que las fallas efímeras tengan menos probabilidades de causar daños al usuario
- Agregar servicios más pequeños que comparten algún modo de falla
- Establecer umbrales de SLO acordes con el impacto real de una solicitud fallida
Objetivos de disponibilidad extrema
Los servicios con un objetivo de disponibilidad extremadamente bajo o extremadamente alto pueden requerir una consideración especial. Por ejemplo, considere un servicio que tiene un objetivo de disponibilidad del 90%. La Tabla 5-8 dice que se pague cuando se consume el 2% del presupuesto de error en una sola hora. Debido a que una interrupción del 100% consume solo el 1,4% del presupuesto en esa hora, esta alerta nunca podría activarse. Si sus presupuestos de error se establecen para períodos de tiempo prolongados, es posible que deba ajustar sus parámetros de alerta.
Para los servicios con un objetivo de disponibilidad extremadamente alto, el tiempo hasta el agotamiento para una interrupción del 100% es extremadamente pequeño. Una interrupción del 100% de un servicio con una disponibilidad mensual objetivo del 99,999% agotaría su presupuesto en 26 segundos, que es más pequeño que el intervalo de recopilación de métricas de muchos servicios de monitoreo, y mucho menos el tiempo de un extremo a otro para generar una alerta y pasarlo a través de sistemas de notificación como correo electrónico y SMS. Incluso si la alerta va directamente a un sistema de resolución automatizado, el problema puede consumir por completo el presupuesto de error antes de que pueda mitigarlo.
Recibir notificaciones de que solo te quedan 26 segundos de presupuesto no es necesariamente una mala estrategia; simplemente no es útil para defender el SLO. La única forma de defender este nivel de confiabilidad es diseñar el sistema de modo que la posibilidad de una interrupción del 100% sea extremadamente baja. De esa manera, puede solucionar problemas antes de consumir el presupuesto. Por ejemplo, si inicialmente implementa ese cambio a solo el 1% de sus usuarios y quema su presupuesto de errores a la misma tasa del 1%, ahora tiene 43 minutos antes de agotar su presupuesto de errores. Consulte los lanzamientos de Canarying para conocer las tácticas sobre el diseño de un sistema de este tipo.
Alerta a escala
Cuando amplíe su servicio, asegúrese de que su estrategia de alerta sea igualmente escalable. Puede tener la tentación de especificar parámetros de alerta personalizados para servicios individuales. Si su servicio comprende 100 microservicios (o lo que es lo mismo, un solo servicio con 100 tipos de solicitudes diferentes), este escenario acumula muy rápidamente trabajo y carga cognitiva que no escala.
En este caso, recomendamos encarecidamente no especificar la ventana de alerta y los parámetros de velocidad de combustión de forma independiente para cada servicio, porque hacerlo rápidamente se vuelve abrumador. 5 Una vez que decida sus parámetros de alerta, aplíquelos a todos sus servicios.
Una técnica para administrar una gran cantidad de SLO es agrupar los tipos de solicitud en depósitos de requisitos de disponibilidad aproximadamente similares. Por ejemplo, para un servicio con SLO de disponibilidad y latencia, puede agrupar sus tipos de solicitud en los siguientes depósitos:
CRITICAL
- Para los tipos de solicitud que son los más importantes, como una solicitud cuando un usuario inicia sesión en el servicio.
HIGH_FAST
- Para solicitudes con requisitos de alta disponibilidad y baja latencia. Estas solicitudes involucran una funcionalidad interactiva central, como cuando un usuario hace clic en un botón para ver cuánto dinero ha ganado su inventario publicitario este mes.
HIGH_SLOW
- Para una funcionalidad importante pero menos sensible a la latencia, como cuando un usuario hace clic en un botón para generar un informe de todas las campañas publicitarias de los últimos años, y no espera que los datos regresen instantáneamente.
LOW
- Para solicitudes que deben tener cierta disponibilidad, pero para las que las interrupciones son en su mayoría invisibles para los usuarios, por ejemplo, controladores de sondeo para notificaciones de cuentas que pueden fallar durante largos períodos de tiempo sin impacto en el usuario.
NO_SLO
- Para la funcionalidad que es completamente invisible para el usuario, por ejemplo, lanzamientos oscuros o funcionalidad alfa que está explícitamente fuera de cualquier SLO.
Al agrupar las solicitudes en lugar de colocar objetivos únicos de disponibilidad y latencia en todos los tipos de solicitudes, puede agrupar las solicitudes en cinco depósitos, como en el ejemplo de la Tabla 5-10 .
| SOLICITAR CLASE | DISPONIBILIDAD | LATENCIA AL 90% 6 | LATENCIA AL 99% |
|---|---|---|---|
CRITICAL
| 99.99% | 100 ms | 200 ms |
HIGH_FAST
| 99.9% | 100 ms | 200 ms |
HIGH_SLOW
| 99.9% | 1000 ms | 5000 ms |
LOW
| 99% | Ninguna | Ninguna |
NO_SLO
| Ninguna | Ninguna | Ninguna |
Estos depósitos brindan suficiente fidelidad para proteger la felicidad del usuario, pero implican menos esfuerzo que un sistema que es más complicado y costoso de administrar y que probablemente se corresponda con más precisión con la experiencia del usuario.
Conclusión
Si establece SLO significativos, entendidos y representados en métricas, puede configurar las alertas para notificar a la persona que llama solo cuando hay amenazas específicas procesables para el presupuesto de errores.
Las técnicas para alertar sobre eventos importantes van desde alertar cuando su tasa de error supera su umbral de SLO hasta usar múltiples niveles de velocidad de combustión y tamaños de ventana. En la mayoría de los casos, creemos que la técnica de alerta de múltiples ventanas y múltiples velocidades de combustión es el enfoque más apropiado para defender los SLO de su aplicación.
Esperamos haberle proporcionado el contexto y las herramientas necesarias para tomar las decisiones de configuración adecuadas para su propia aplicación y organización.
1 En ocasiones, las cláusulas de duración pueden resultar útiles cuando se filtra el ruido efímero durante períodos muy breves. Sin embargo, aún debe tener en cuenta las desventajas que se enumeran en esta sección.
2 Como se describe en la introducción a la Ingeniería de confiabilidad del sitio , las páginas y los tickets son las únicas formas válidas de lograr que un humano actúe.
3 La sección Qué medir: el uso de SLI recomienda un estilo de SLI que se escala de acuerdo con el impacto en el usuario.
4 Consulte “Sobrecargas y fallas” en Ingeniería de confiabilidad del sitio .
5 Con la excepción de los cambios temporales en los parámetros de alerta, que son necesarios cuando está solucionando una interrupción en curso y no necesita recibir notificaciones durante ese período.
6 El noventa por ciento de las solicitudes superan este umbral.
Licencia
: Publicado por O’Reilly Media, Inc. bajo licencia CC BY-NC-ND 4.0
Relacionado
Como una de las estructuras de control básicas en la programación, los bucles son casi una adición diaria al código que escribimos. El bucle forEach clásico es uno de los primeros fragmentos de código que aprendemos a escribir como programadores. Si fueras un desarrollador de Javascript, sabrías que Javascript no es ajeno a la iteración a través de los elementos de una matriz o un mapa ¡SEGUIR LEYENDO!
Como sabemos, Sci-hub es un sitio web increíble con millones de artículos de investigación para todos los estudiantes universitarios y académicos. El sitio web de Sci-Hub se encarga de obtener los artículos de investigación y artículos de pago utilizando las credenciales que se filtran. La fuente de credenciales utilizada por este sitio web no está clara. Sin embargo, se supone que muchas de ellas son donadas, ¡SEGUIR LEYENDO!
Aunque haya sido usuario de Windows durante décadas, el sistema operativo es tan amplio y complejo que siempre existen características útiles, pero menos conocidas, que podrían sorprenderte. En este sentido, he identificado diez funciones poco conocidas de Windows que pueden potenciar su eficiencia, comodidad e incluso su experiencia de uso lúdico en su PC.

- Procesador Dual-Core Intel Pentium Gold 4425Y (2...
- Memoria RAM de 8 GB LPDDR3
- Disco SSD de 128 GB
El rumor en torno a las criptomonedas no se desvanece por mucho que existan grandes pesimistas alrededor de los malos rumores. Entonces, si consideras invertir en el mundo de las criptomonedas, deberías estar atento a las criptomonedas que se espera que tengan un buen desempeño para el resto de 2021. En los últimos tiempos, los tokens DeFi están recibiendo toda la atención y es más que ¡SEGUIR LEYENDO!
Los cambios de paradigma revolucionarios debido a los desarrollos de la robótica en todo el mundo están generando nuevos puntos de vista en muchos sectores, entre ellos en los de la industria y la tecnología. Con la ayuda de la Inteligencia Artificial, la tecnología produce resultados innovadores cada segundo y el campo de la robótica define y reconfigura su uso a cada instante. Cada día que ¡SEGUIR LEYENDO!
Bienvenidos desarrolladores web y de software, estamos en los inicios de 2023 y es posible que muchos se esten planteado sus objetivos para lo largo del año. Con anterioridad ya he compartidos las rutas de aprendizaje para un desarrollador front-end, un desarrollador full-stack o un desarrollador back-end entre otros muchos contenidos más. En este artículo, me gustaría compartir algunos de los mejores frameworks y bibliotecas para ¡SEGUIR LEYENDO!
GitHub es el lugar que debes buscar cuando intentas mejorar como desarrollador, toda la información que necesitas está disponible en algún repositorio que alguien ya se ha molestado en indexar. Sin embargo, la parte complicado es encontrar el repositorio más adecuado. Es fácil sentirse perdido en todos los repositorios disponibles dentro de GitHub. Para ayudarte, he elaborado una lista de 10 repositorios de GitHub que pueden ¡SEGUIR LEYENDO!